Extracting Maximum Number of Pages
Let's say you're building an extractor, and you want to generate a list of URLs Using the URL Generator for a website with many pages (reviews, products, etc). How do you determine the number of pages to generate? If it's just a single webpage, you can just look at the site and take a note of the total number of pages.

This gets a lot harder and time consuming once you start increasing the number of webpages. How about 100 webpages? You'd have to go through every webpage and visually keep track of the total number of pages.
This article will provide the detailed step-by-step tips and tricks needed to build an extractor that grabs the maximum number of pages for websites.
What You'll Need
- A simple understanding of HTML and XPath
- A browser with developer tools (Almost all do!)
For this example, we'll be going through the process of grabbing the maximum number of reviews for a Walmart product page.
Locate The Page Numbers Using XPath
If you're not familiar with using a browser's developer tools, this may look very confusing, but it's not as bad as it looks! I'll be using Chrome, but this will work with other browsers as well.
1. Create a new extractor for the webpage.
For this example, I'll be using https://www.walmart.com/search/?cat_id=0&query=Ben+%26+Jerry%27s
If any fields get automatically populated, go ahead and clear you table.
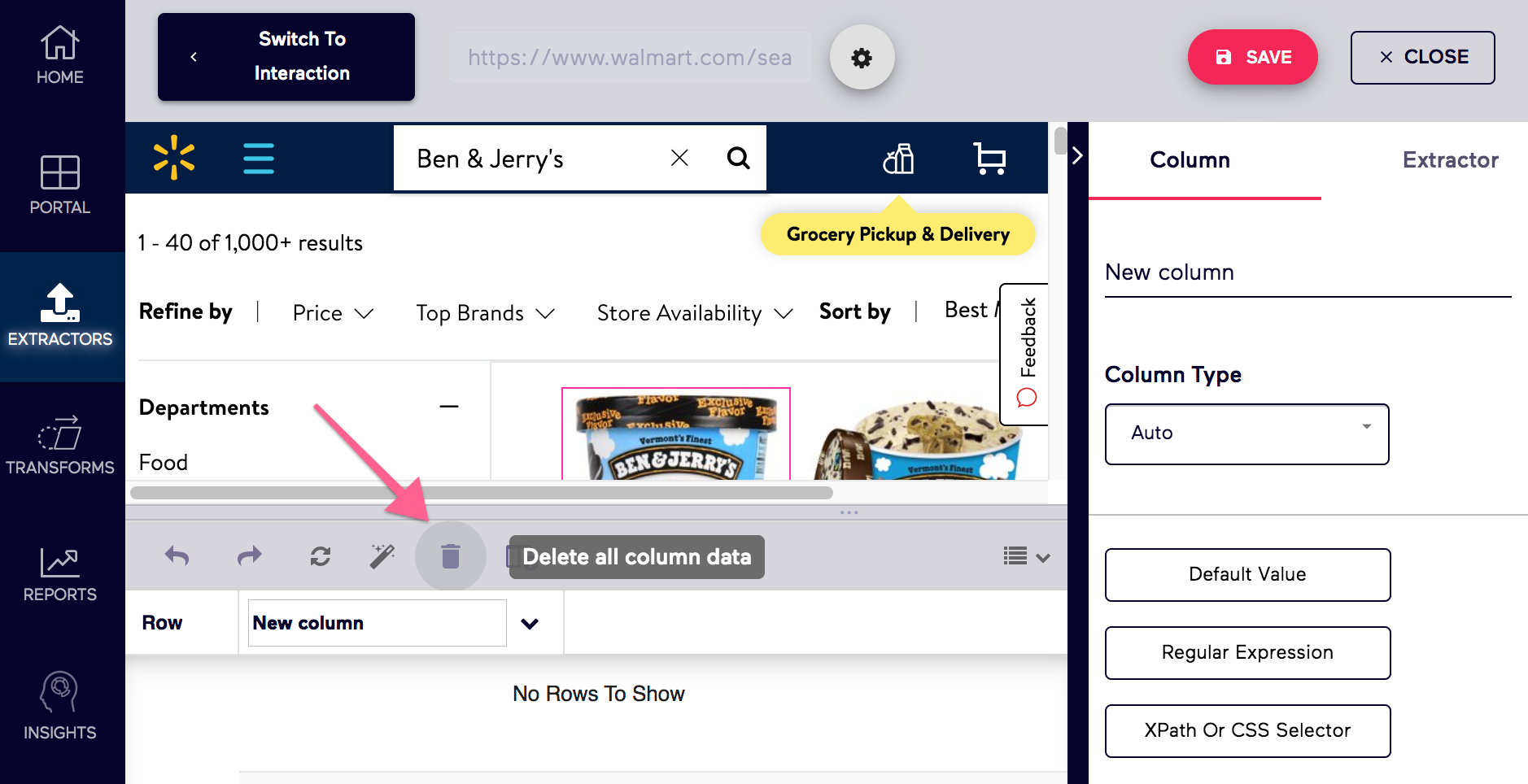
2. With the empty row, enable XPath by selecting "Use Manual Xpath"
This will open the XPath input field for this column.
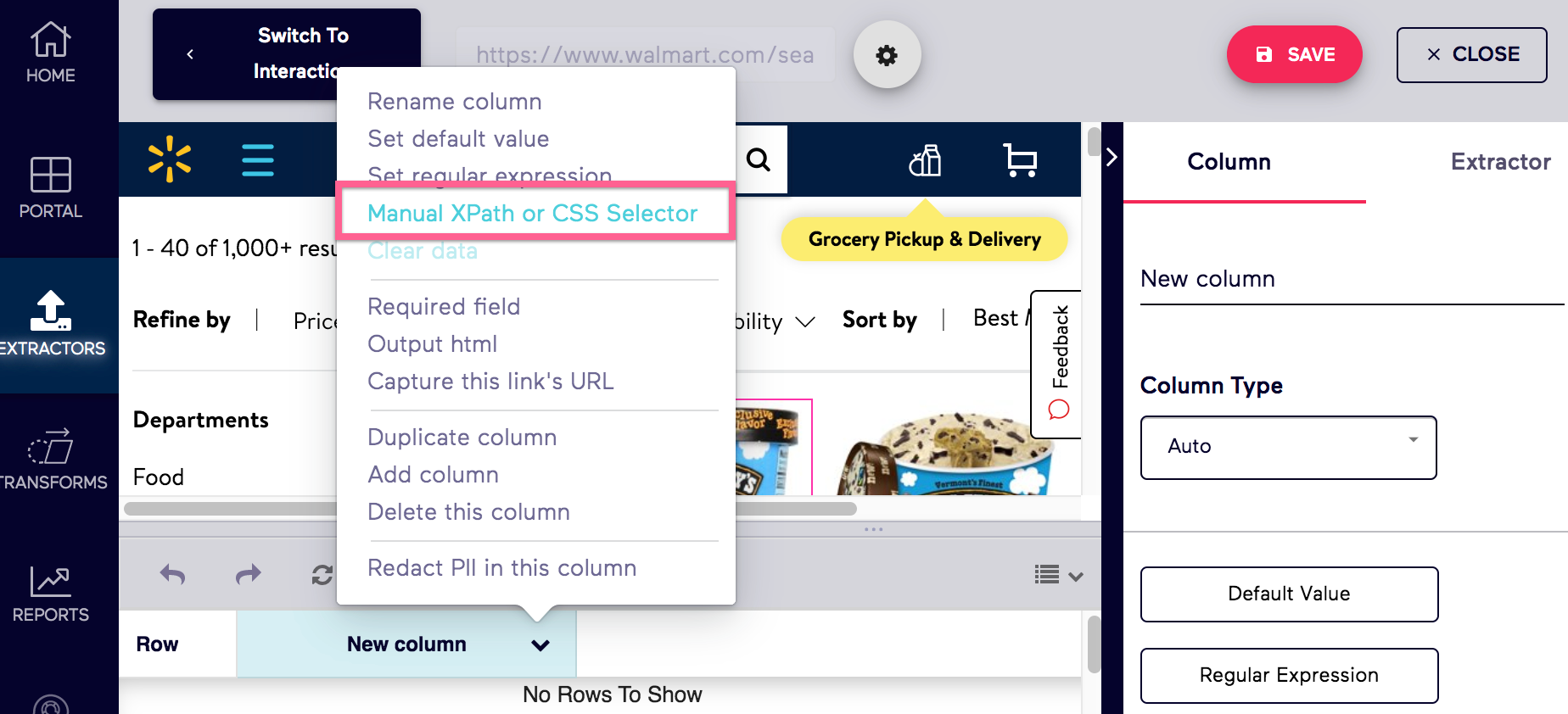
3. Right click to inspect the page numbers
This will open the browser's developer tools with the element highlighted.
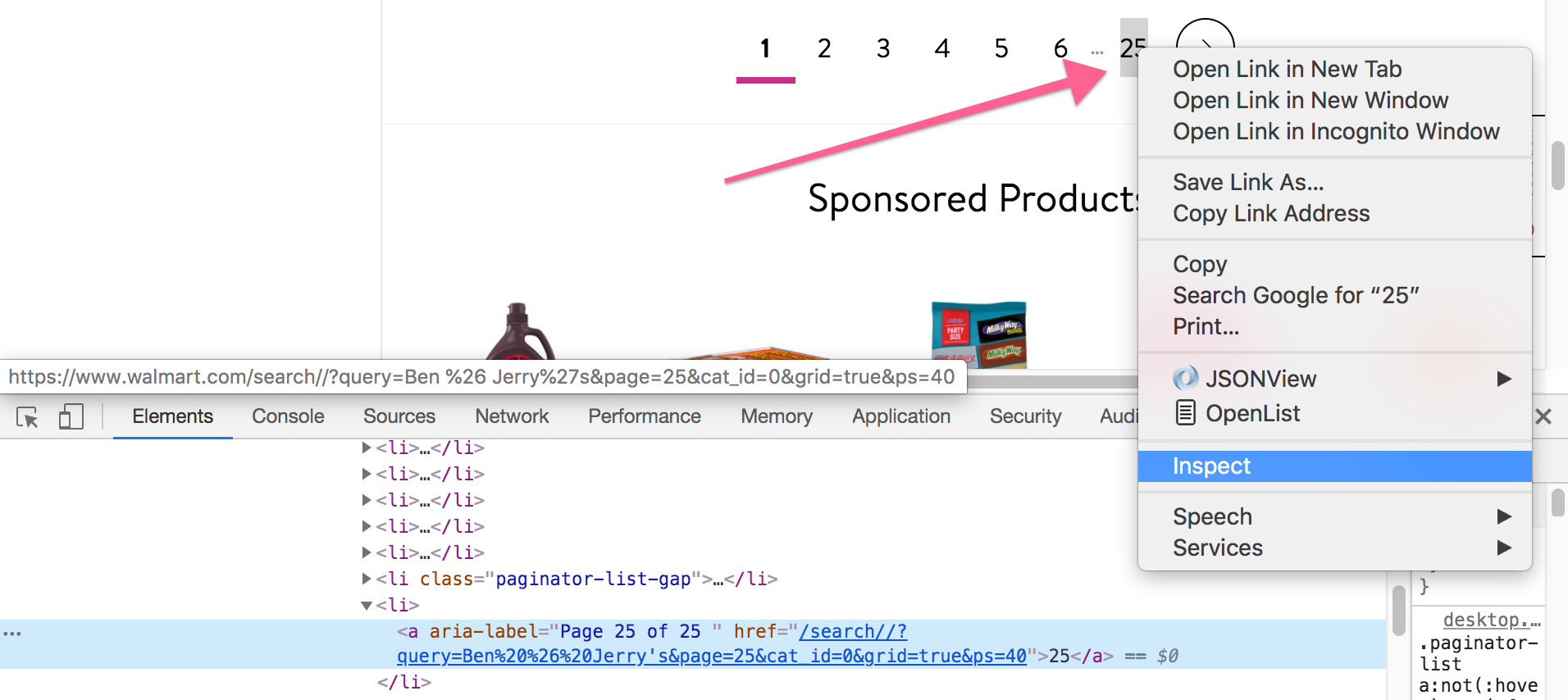
4. Grab the XPath for the page number
If you look at the way this HTML is formatted, there seems to be many tags with tags that look the same. If you expand them, you'll see the number for the pages. This must be it!

When looking at the tags, you can see that there is an attribute, aria-label, that contains the word Page.
The XPath for the page number is
//a[contains(@aria-label,'Page')]
Modify XPath to Display Correct Number
Congrats! You made an XPath query to the page numbers! Let's paste that into the XPath input field you enabled in Step 2 and hit Apply.
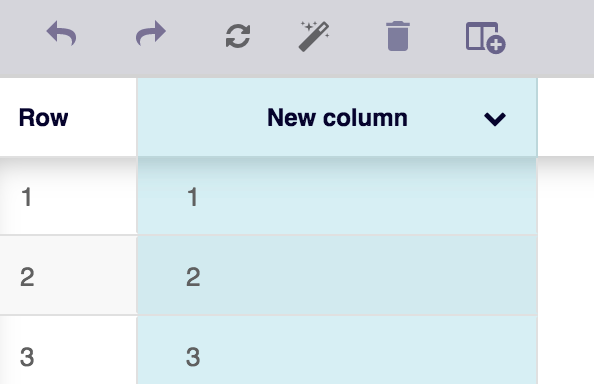
Uh oh... that doesn't look right. As you can see, the XPath is grabbing all the button tags that match that query. We only want the last one.
5. Grab only the last element from the XPath results
The XPath snippet below is used to grab only the last element of XPath results. I'd take a note of this because this is really useful for other use cases!
(*****XPATH _QUERY>*****)[last()]
We will replace the text with the XPath we came up with in Step 4
(//a[contains(@aria-label,'Page')])[last()]
Modify XPath to Include Single Pages
Let's grab that XPath snippet and replace the query in the XPath input field.
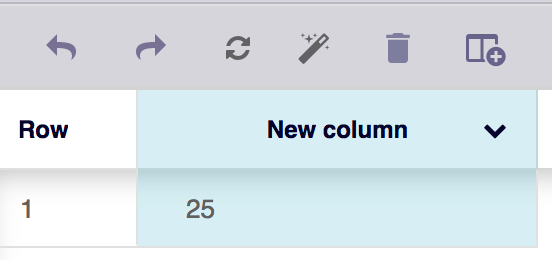
It works! Except...
What happens if the product link only has one page?
Take a look at this product link https://www.walmart.com/ip/6-Pack-RO-TEL-Chili-Fixin-s-Seasoned-Diced-Tomatoes-and-Green-Chilies-10-Ounce/47234504
There's one page of reviews, but there are no links for pages! Most websites will not show the number of pages if there is only a single page. With the XPath query we made in Step 5, it would return a blank value for the row. That's not good!
6. Set a default value of 1 if there is no XPath results
The XPath snippet below is used to set a default value if the XPath results is empty. I'd take a note of this because this is really useful for other use cases!
concat(,substring('', 1 div not()))
We're going to replace the text with the XPath we came up with in Step 5. We will set the text as 1.
concat((//button[contains(@aria-label,'Page')])[last()],substring('1', 1 div not((//button[contains(@aria-label,'Page')])[last()])))
And You're Done!
Let's apply the XPath we came up with in Step 6 and save our extractor. Let's test the extractor by adding
and
https://www.walmart.com/ip/Ben-Jerry-s-Gingersnap-Limited-Batch-Ice-Cream-1-pt/15754303 (76 Pages)
to the extractor by Adding a List of URLs and running the URLs!
If you followed every step properly (and assuming that Walmart doesn't change their website layout), your data should look like this
