Infinite Scroll and Pagination URLs That Don't Change
What is Infinite scroll?
Many webpages consist of content that requires you to scroll the browser window or click Load More to see more information. Some webpages, search results for example, can go on seemingly forever, and thus the term infinite scroll.
What's the problem?
Handling infinite scroll can be tricky because the URL generally remains static (it doesn?t change, even when you?re on a different page). Websites handle this situation in different ways structurally. While it is not always possible to get around the problem, the key is finding the underlying URL pattern for the different pages or pagination, even when the pattern is not explicit in the URL.
Working through an example: Staples category
The http://www.staples.com/Notebooks-Pads/cat_CG3783 webpage consists of both infinite scroll initially and then a LOAD MORE button farther down the page.
To compensate for the infinite scroll, perform the following steps:
Step 1. Opening Chrome DevTools
To find the underlying URL, Import.io recommends using Google Chrome.
Open Chrome and navigate to the Staples webpage.
Right-click on the page and select Inspect. The DevTools inspector appears.
Step 2. Clearing the Network tab
Click the Network tab.
Click the Clear icon (next to the red circle near the upper left of the inspector window) to clear any existing activity.
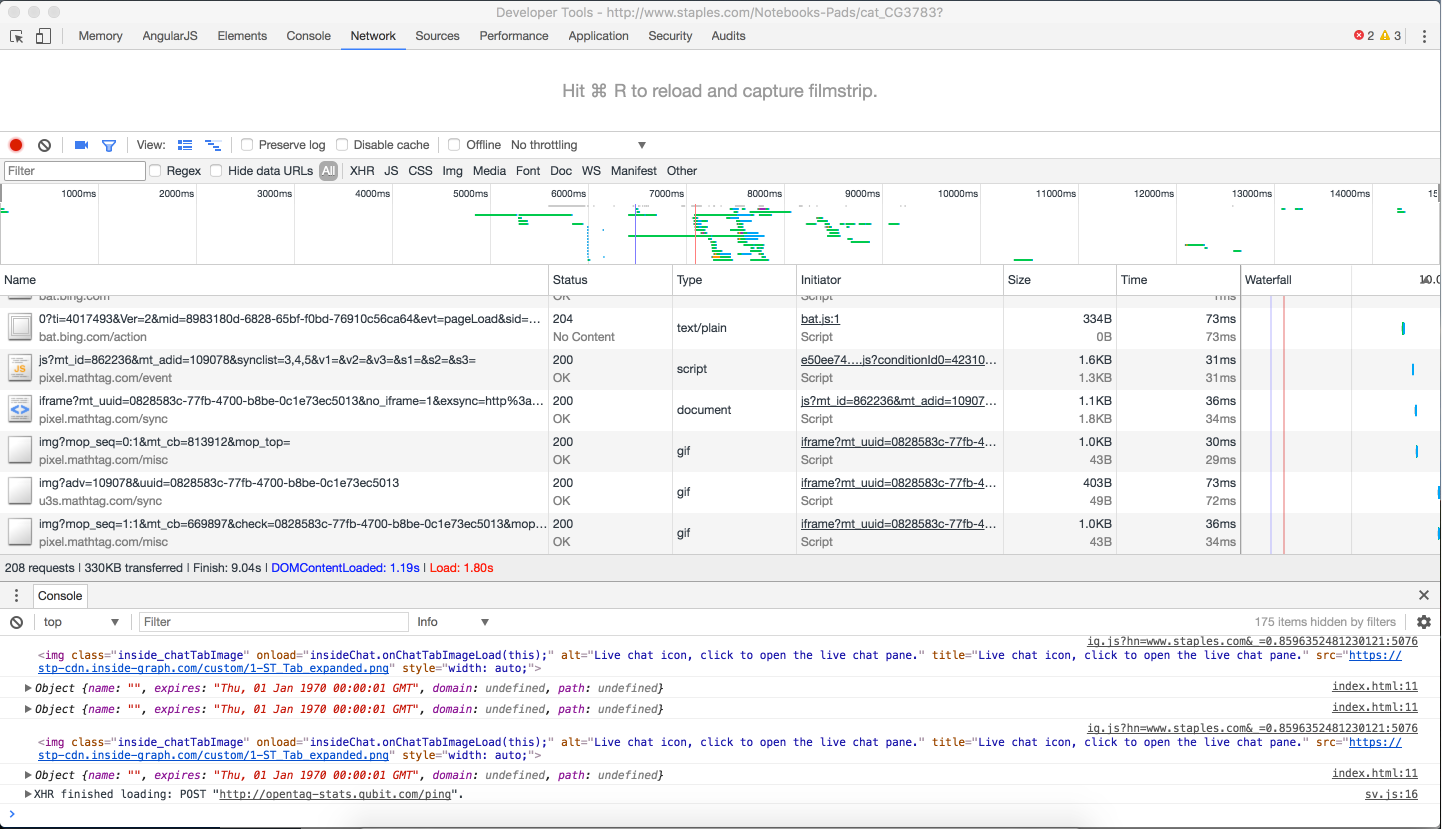
Step 3. Locating the second page of content
Click the XHR tab (under the Filter search box), to view the XHR requests.
Scroll down the page, displaying more content, until the LOAD MORE button appears.
Click LOAD MORE. XHR requests appear in the inspector.
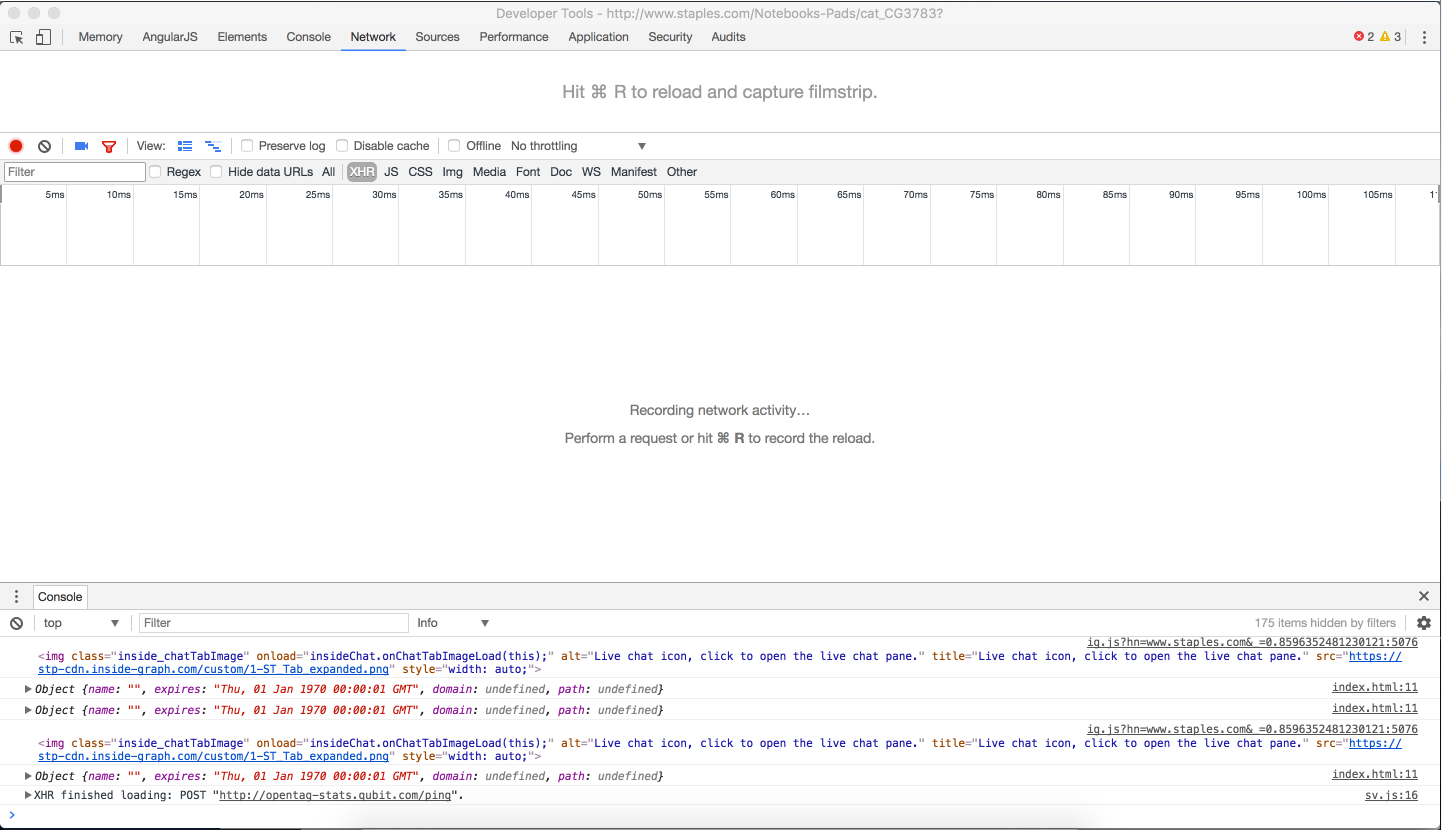
Step 4. Viewing the XHR request header
Hover over the items in the Name column and locate http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=2&zipcode=94566&productTile=secondaryDealsData.
Select this item. Several tabs appear to the right of the Name list.
Click the Headers tab.
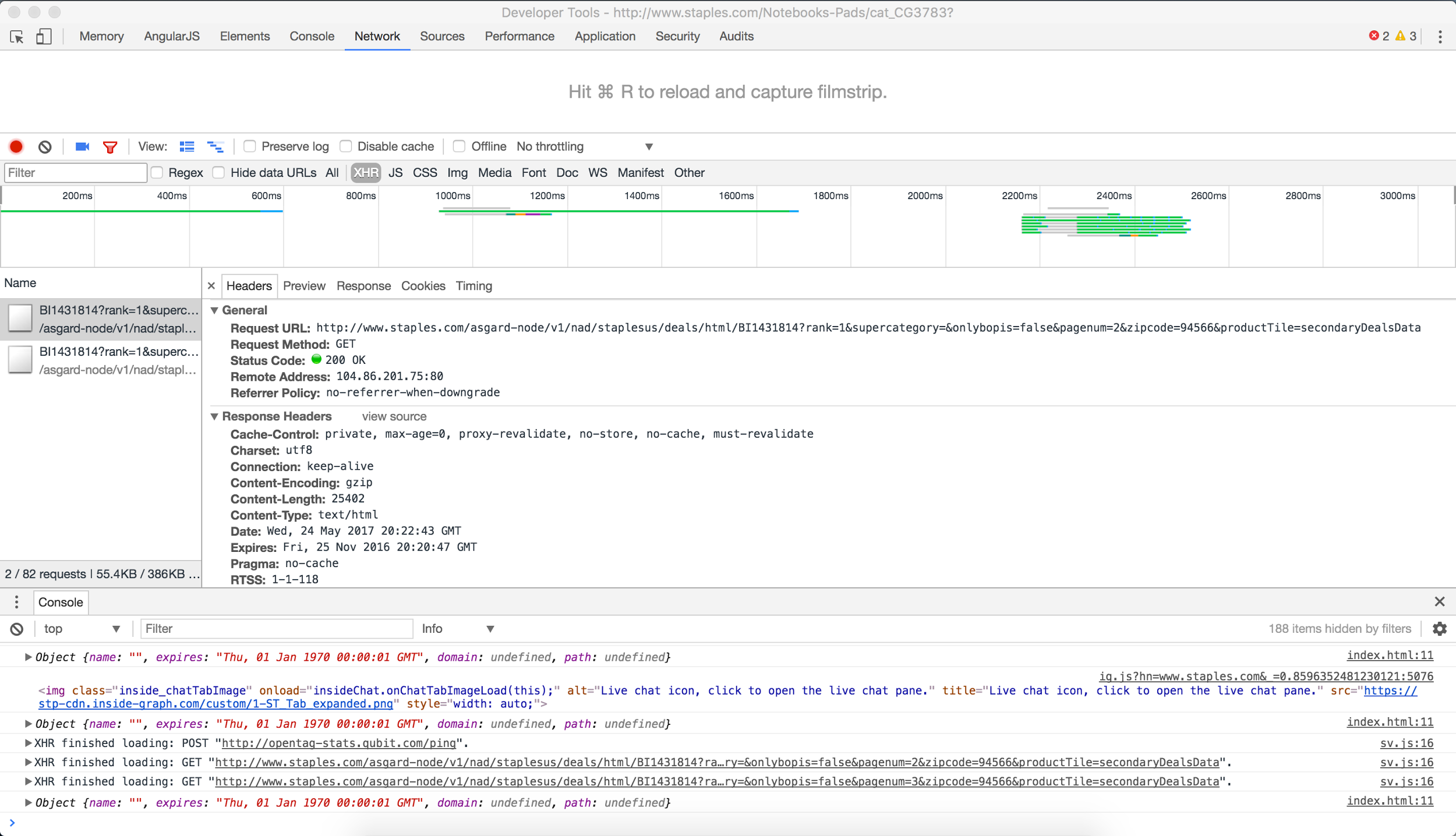
Step 5. Identifying the page component of the URL
In the Request URL, notice pagenum=2. Pagenum is the URL parameter that contains the actual page number of the displayed page. Navigating to this URL directly skips straight to the second page of content in the underlying data structure.
Now you know how the website really paginates, and thus, how to create your extractor.
Step 6. Creating your extractor
Create your extractor using the following URL: http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=2&zipcode=94566&productTile=secondaryDealsData
Step 7. Adding the rest of the URLs and running the extractor
From the dashboard, click the Settings tab.
Add the rest of the URLs:
- http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=1&zipcode=94566&productTile=secondaryDealsData
- http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=2&zipcode=94566&productTile=secondaryDealsData
- http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=3&zipcode=94566&productTile=secondaryDealsData
- http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=4&zipcode=94566&productTile=secondaryDealsData
- http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=5&zipcode=94566&productTile=secondaryDealsData
- http://www.staples.com/asgard-node/v1/nad/staplesus/deals/html/BI1431814?rank=1&supercategory=&onlybopis=false&pagenum=6&zipcode=94566&productTile=secondaryDealsData
and so forth. Save and run your extractor.
What if I get a JSON response?
If a JSON response appears when you paste a URL in step 6 or step 7, add the following OPT parameter to the end of each URL:
#[!opt!]{"type":"json"}[/!opt!]
What if I run into a POST request or another issue?
If in step 4, the request method of the XHR request is POST (or you run into another issue), contact support@import.io for assistance.